Regresión Lineal Simple
Modelo que estima la relación lineal entre una variable independiente y una dependiente. Se construye desde cero: función de pérdida ECM, búsqueda de parámetros y solución analítica por mínimos cuadrados.
Introducción
El objetivo es encontrar los parámetros \(m\) y \(b\) de una recta \(\hat{y} = mx + b\) que minimice el error total entre los valores observados y los predichos. Conocidos esos parámetros, el modelo permite estimar \(y\) para valores de \(x\) no observados.
La recta y = mx + b
Una línea recta en un plano 2D queda completamente definida por dos parámetros:
- m — pendiente: cuánto cambia \(\hat{y}\) cuando \(x\) aumenta en 1 unidad
- b — ordenada al origen (intercepto): el valor de \(\hat{y}\) cuando \(x = 0\)
def valores_estimados(m, b, x):
"""Calcula y_hat = mx + b para cada valor en x."""
return [m * xi + b for xi in x]
# Con NumPy, mucho más conciso:
def calcular_y(m, b, x):
return m * x + bFunción de pérdida: ECM
Para medir qué tan buena es nuestra recta, necesitamos cuantificar el error total entre los valores reales \(y_i\) y los estimados \(\hat{y}_i\). El Error Cuadrático Medio es la métrica estándar:
Se eleva al cuadrado por dos razones: para que los errores positivos y negativos no se cancelen, y para penalizar más los errores grandes.
def error_cuadratico_medio(y_real, y_estimado):
total = 0
for i in range(len(y_real)):
total += (y_real[i] - y_estimado[i]) ** 2
return total / len(y_real)
# Con NumPy:
import numpy as np
def ecm(y_real, y_estimado):
return ((np.array(y_real) - np.array(y_estimado)) ** 2).mean()Búsqueda por fuerza bruta
Una primera estrategia es probar muchos valores posibles de m y b, calcular el ECM para cada combinación y quedarnos con los que minimizan el error. Es ineficiente pero ilustra perfectamente la idea de optimización:
import pandas as pd
df = pd.read_csv("data/csvs/examenes.csv").sample(100)
x = list(df["study_hours"])
y = list(df["exam_score"])
# Búsqueda en una dimensión: solo variamos m, fijamos b=40
errores = []
pendientes = range(-10, 30)
for m in pendientes:
y_hat = valores_estimados(m, 40, x)
ecm_actual = error_cuadratico_medio(y, y_hat)
errores.append(ecm_actual)
pendiente_optima = pendientes[errores.index(min(errores))]
print(f"Mejor pendiente encontrada: {pendiente_optima}")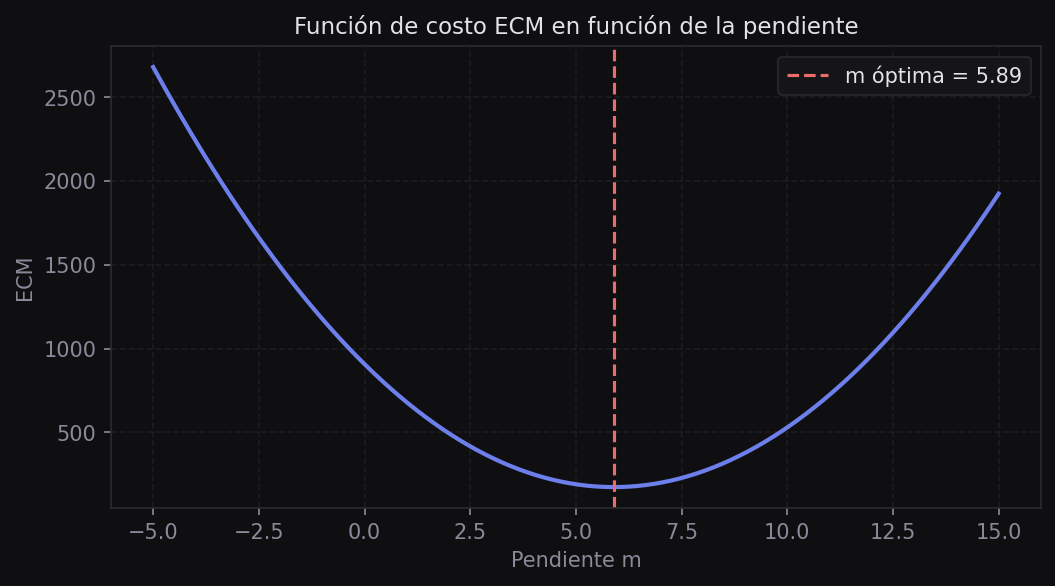
Ejemplo Búsqueda en dos dimensiones (m y b)
Al extender la búsqueda a ambos parámetros simultáneamente, el espacio de soluciones se convierte en una superficie. Buscamos el punto más bajo de esa superficie:
pendientes = range(-10, 10)
ordenadas = range(20, 50)
ecm_minimo = float("inf")
mejor_m = mejor_b = None
for m in pendientes:
for b in ordenadas:
y_hat = valores_estimados(m, b, x)
ecm_actual = error_cuadratico_medio(y, y_hat)
if ecm_actual < ecm_minimo:
ecm_minimo = ecm_actual
mejor_m, mejor_b = m, b
print(f"m={mejor_m}, b={mejor_b}, ECM={ecm_minimo:.2f}")El problema con fuerza bruta es que el número de combinaciones crece exponencialmente. Para espacios continuos o de alta dimensión, necesitamos métodos más inteligentes: la fórmula cerrada o el gradiente descendente.
Fórmula cerrada (mínimos cuadrados)
La fórmula cerrada resuelve el problema de minimización de forma analítica, derivando el ECM respecto a m y b e igualando a cero. El resultado son dos ecuaciones explícitas:
Pendiente óptima
Ordenada al origen óptima
import numpy as np
x = np.array(df["study_hours"])
y = np.array(df["exam_score"])
n = len(x)
# Pendiente
m = (n * (x * y).sum() - x.sum() * y.sum()) / \
(n * (x ** 2).sum() - x.sum() ** 2)
# Ordenada al origen
b = y.mean() - m * x.mean()
print(f"m = {m:.4f}")
print(f"b = {b:.4f}")
# Predicciones
y_hat = m * x + bImplementación completa con visualización
import matplotlib.pyplot as plt
# Ajustar modelo
x = np.array(df["study_hours"])
y = np.array(df["exam_score"])
n = len(x)
m = (n * (x * y).sum() - x.sum() * y.sum()) / (n * (x**2).sum() - x.sum()**2)
b = y.mean() - m * x.mean()
y_hat = m * x + b
# Visualización
x_line = np.linspace(x.min(), x.max(), 100)
y_line = m * x_line + b
fig, ax = plt.subplots(figsize=(7, 5))
ax.scatter(x, y, alpha=0.5, s=20, label="Datos reales")
ax.plot(x_line, y_line, color="#6c7fea", linewidth=2, label=f"y = {m:.2f}x + {b:.2f}")
ax.set_xlabel("Horas de estudio")
ax.set_ylabel("Calificación")
ax.legend()
plt.show()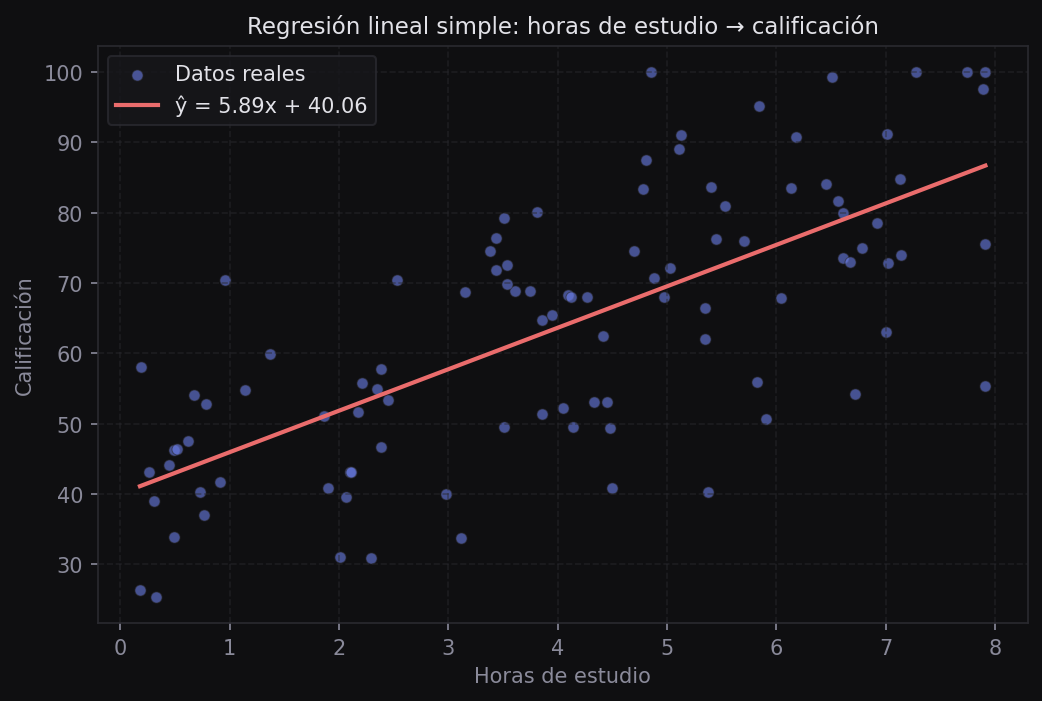
Métricas de evaluación
Además del ECM, se usan otras métricas para evaluar la calidad del modelo:
# Error Cuadrático Medio
ecm_val = ((y - y_hat) ** 2).mean()
# Raíz del Error Cuadrático Medio (mismas unidades que y)
recm = ecm_val ** 0.5
# Coeficiente de determinación R²
ss_res = ((y - y_hat) ** 2).sum()
ss_tot = ((y - y.mean()) ** 2).sum()
r2 = 1 - ss_res / ss_tot
print(f"ECM: {ecm_val:.2f}")
print(f"RECM: {recm:.2f}")
print(f"R²: {r2:.4f}")El coeficiente \(R^2\) indica qué fracción de la variabilidad en \(y\) es explicada por el modelo. Un \(R^2 = 0.85\) significa que el modelo explica el 85% de la variación. Un \(R^2 = 0\) significa que el modelo no es mejor que simplemente predecir el promedio.