Gradiente Descendente
Algoritmo de optimización iterativa basado en el cálculo de la derivada de la función de pérdida. Permite encontrar los parámetros del modelo cuando no existe o no es práctico usar una solución analítica.
Motivación: limitaciones de la fórmula cerrada
La solución analítica de mínimos cuadrados es exacta para regresión lineal simple, pero presenta restricciones que la hacen impráctica en escenarios más generales:
- Requiere calcular la inversa de \(X^T X\), lo que se vuelve costoso con muchas variables
- No existe fórmula cerrada para la mayoría de los modelos más complejos (redes neuronales, por ejemplo)
- En datasets muy grandes, el cálculo matricial puede ser prohibitivamente lento
El gradiente descendente ofrece una alternativa general: en lugar de calcular la solución exacta, la busca iterativamente.
La derivada como guía
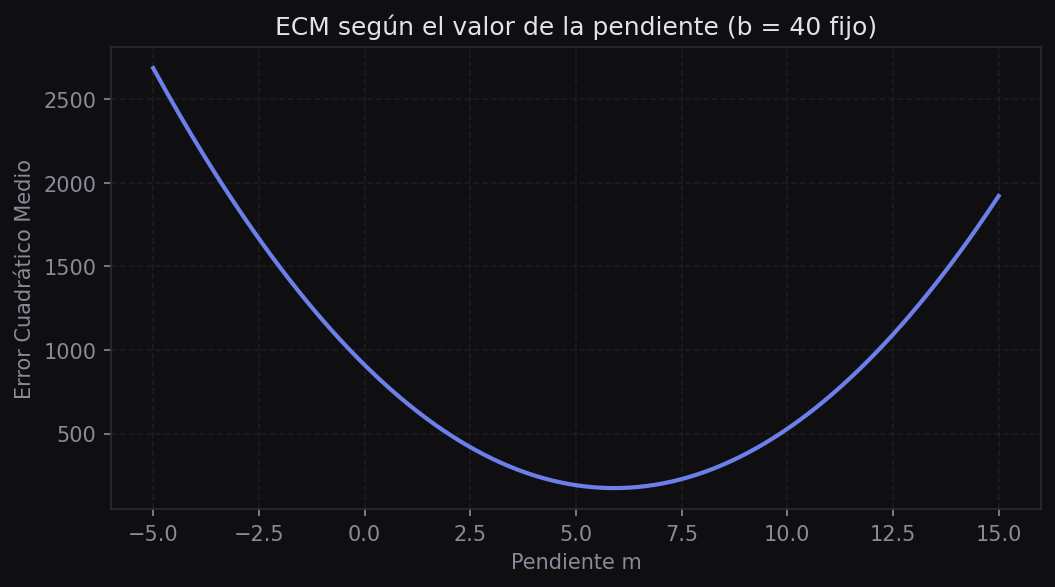
Imagina que estás parado en una montaña con niebla y quieres bajar al valle. No puedes ver el panorama completo, pero puedes sentir la inclinación del terreno bajo tus pies. Si siempre das pasos en la dirección de mayor pendiente descendente, eventualmente llegarás al punto más bajo.
La derivada de la función de pérdida respecto a un parámetro indica exactamente eso: en qué dirección (positiva o negativa) se mueve el error cuando cambiamos ese parámetro.
Si la derivada \(\frac{\partial ECM}{\partial m} > 0\), el ECM aumenta cuando aumentamos m, así que debemos disminuir m. Si es negativa, debemos aumentarla. En ambos casos, nos movemos en la dirección opuesta al gradiente.
El algoritmo
El gradiente descendente sigue estos pasos de forma repetida hasta converger:
- Inicializar los parámetros con algún valor (por ejemplo, 0 o valores aleatorios)
- Calcular las predicciones con los parámetros actuales
- Calcular el error (ECM)
- Calcular el gradiente — la derivada del ECM respecto a cada parámetro
- Actualizar cada parámetro restándole el gradiente multiplicado por el learning rate
- Repetir desde el paso 2
Regla de actualización
Para cada parámetro \(\theta\) (que puede ser m o b):
Donde \(\alpha\) (alpha) es el learning rate — un número positivo pequeño que controla el tamaño del paso.
Learning rate
El learning rate es el hiperparámetro más crítico del gradiente descendente:
- Muy grande: los pasos son grandes y el algoritmo puede saltar sobre el mínimo, oscilando o divergiendo
- Muy pequeño: los pasos son minúsculos y el algoritmo tarda demasiado en converger
- Valor adecuado: converge de manera estable en un número razonable de iteraciones
Valores típicos de prueba: 0.1, 0.01, 0.001. Se elige mediante experimentación.
Derivación del gradiente para regresión lineal
Para el ECM con modelo \(\hat{y} = mx + b\), las derivadas parciales son:
En la práctica se omite el factor 2 (no cambia la dirección del gradiente) y con NumPy la implementación es directa:
Implementación
import numpy as np
import pandas as pd
# Funciones del módulo utils.py
def calcular_y(x, m, b):
return x * m + b
def ecm(y_real, y_est):
return ((y_real - y_est) ** 2).mean()
def gradiente_m(m, alpha, b, x, y_real):
"""Actualiza m usando el gradiente del ECM."""
gradiente = (2 * (x * (m * x + b - y_real))).mean()
return m - alpha * gradiente
def gradiente_b(b, alpha, m, x, y_real):
"""Actualiza b usando el gradiente del ECM."""
gradiente = (2 * (m * x + b - y_real)).mean()
return b - alpha * gradiente
# --- Entrenamiento ---
df = pd.read_csv("data/csvs/examenes.csv").sample(100)
x = np.array(df["study_hours"])
y = np.array(df["exam_score"])
# Inicializar parámetros
m = 0.0
b = 0.0
alpha = 0.01
n_iter = 1000
for i in range(n_iter):
m = gradiente_m(m, alpha, b, x, y)
b = gradiente_b(b, alpha, m, x, y)
if i % 100 == 0:
print(f"Iteración {i:4d} — ECM: {ecm(y, calcular_y(x, m, b)):.2f}")
print(f"\nResultado: m={m:.4f}, b={b:.4f}")
Convergencia y diagnóstico
Para verificar que el algoritmo converge, se grafica el ECM en función del número de iteraciones. La curva debe descender y aplanarse:
import matplotlib.pyplot as plt
m, b = 0.0, 0.0
alpha = 0.01
historial_ecm = []
for i in range(1000):
m = gradiente_m(m, alpha, b, x, y)
b = gradiente_b(b, alpha, m, x, y)
historial_ecm.append(ecm(y, calcular_y(x, m, b)))
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(historial_ecm)
ax.set_xlabel("Iteración")
ax.set_ylabel("ECM")
ax.set_title("Convergencia del gradiente descendente")
plt.show()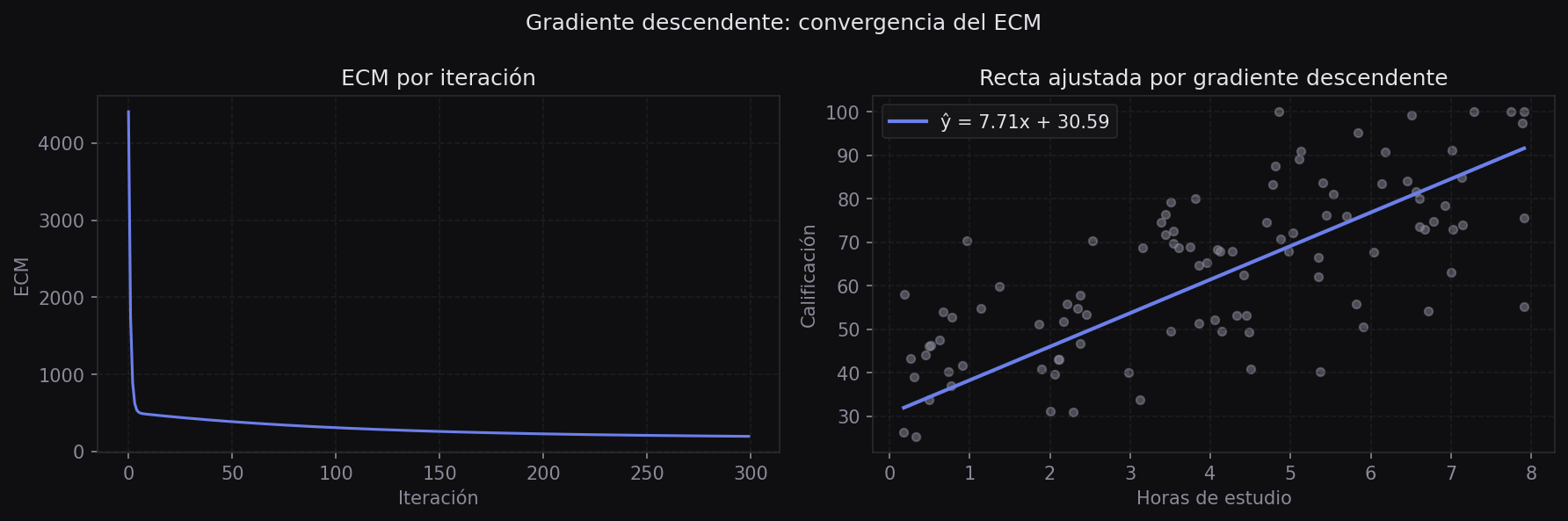
Profundización Variantes del gradiente descendente
Existen tres variantes principales según cuántos datos se usan en cada actualización:
- Batch Gradient Descent: usa todos los datos en cada iteración. Estable pero lento en datasets grandes.
- Stochastic Gradient Descent (SGD): usa un solo dato por iteración. Rápido pero ruidoso.
- Mini-batch Gradient Descent: usa un subconjunto (lote) de datos. Equilibrio entre estabilidad y velocidad. Es el estándar en deep learning.