Pruebas de Hipótesis
Marco estadístico para decidir, con base en una muestra, si existe evidencia suficiente para rechazar una hipótesis sobre la población. Se cubren las pruebas t de Student, ANOVA y chi-cuadrada aplicadas con scipy.
Introducción
La inspección visual de promedios o distribuciones no es suficiente para afirmar que una diferencia entre grupos existe en la población. Las pruebas de hipótesis proveen un procedimiento formal: bajo el supuesto de que no hay diferencia (hipótesis nula), se cuantifica qué tan improbable es el resultado observado.
Hipótesis nula y alternativa
Toda prueba estadística parte de dos hipótesis:
- H₀ (hipótesis nula): no hay efecto, no hay diferencia, no hay asociación. Es el estado de "nada interesante está pasando".
- Hₐ (hipótesis alternativa): sí hay efecto, diferencia o asociación. Es lo que queremos demostrar.
El objetivo de la prueba es decidir si hay suficiente evidencia en los datos para rechazar H₀.
Asumimos que H₀ es verdadera y calculamos la probabilidad de observar lo que vimos (o algo más extremo) si eso fuera cierto. Si esa probabilidad es muy pequeña, concluimos que H₀ probablemente no es verdadera y la rechazamos.
El p-valor
El p-valor es la probabilidad de obtener el resultado observado (o uno más extremo) asumiendo que H₀ es verdadera:
- p-valor < 0.05: rechazamos H₀ al nivel de significancia del 5%
- p-valor ≥ 0.05: no tenemos suficiente evidencia para rechazar H₀
El umbral 0.05 es una convención. En ciencias más exigentes se usa 0.01 o incluso 0.001.
No rechazar H₀ no significa que H₀ sea verdadera. Solo significa que los datos no proporcionan suficiente evidencia para descartarla. La ausencia de evidencia no es evidencia de ausencia.
Prueba t de Student
La prueba t compara las medias de dos grupos para determinar si la diferencia entre ellas es estadísticamente significativa. Se usa cuando:
- La variable de interés es numérica (continua)
- Se comparan dos grupos
Dos muestras independientes
Ejemplo: ¿tienen las mujeres y los hombres calificaciones significativamente diferentes?
import pandas as pd
from scipy.stats import ttest_ind
df = pd.read_csv("data/csvs/examenes.csv")
scores_mujeres = df[df["gender"] == "female"]["exam_score"]
scores_hombres = df[df["gender"] == "male"]["exam_score"]
# H₀: los promedios son iguales
# Hₐ: los promedios son diferentes
t_stat, p_valor = ttest_ind(scores_mujeres, scores_hombres)
print(f"Estadístico t: {t_stat:.4f}")
print(f"P-valor: {p_valor:.4f}")
if p_valor < 0.05:
print("Rechazamos H₀: hay diferencia significativa en calificaciones por género.")
else:
print("No rechazamos H₀: no hay diferencia significativa.")Profundización El estadístico t
El estadístico t mide cuántas desviaciones estándar de diferencia hay entre las medias, relativo a la variabilidad esperada:
Un valor absoluto grande de t (y por tanto un p-valor pequeño) indica que la diferencia entre las medias es grande en relación con la variabilidad de los datos.
Prueba ANOVA
Cuando queremos comparar las medias de tres o más grupos, usar múltiples pruebas t aumenta el riesgo de error. ANOVA (Analysis of Variance) resuelve esto comparando todos los grupos simultáneamente.
ANOVA es la prueba adecuada cuando:
- La variable de interés es numérica
- El factor de agrupación es categórico con 3 o más categorías
Las hipótesis son:
- H₀: todas las medias de los grupos son iguales — \(\mu_1 = \mu_2 = \cdots = \mu_k\)
- Hₐ: al menos una media es diferente
ANOVA en Python
Ejemplo: ¿el método de estudio impacta en la calificación del examen?
from scipy.stats import f_oneway
# Crear una lista con los scores de cada grupo
grupos = []
for metodo in df["study_method"].unique():
filtro = df["study_method"] == metodo
grupos.append(list(df[filtro]["exam_score"]))
# Aplicar ANOVA
f_stat, p_valor = f_oneway(*grupos)
print(f"Estadístico F: {f_stat:.4f}")
print(f"P-valor: {p_valor:.6f}")
if p_valor < 0.05:
print("Rechazamos H₀: el método de estudio sí impacta en el exam_score.")
else:
print("No rechazamos H₀: el método de estudio NO impacta.")Estadístico F: 31.45
P-valor: 0.000000
Rechazamos H₀: el método de estudio sí impacta en el exam_score.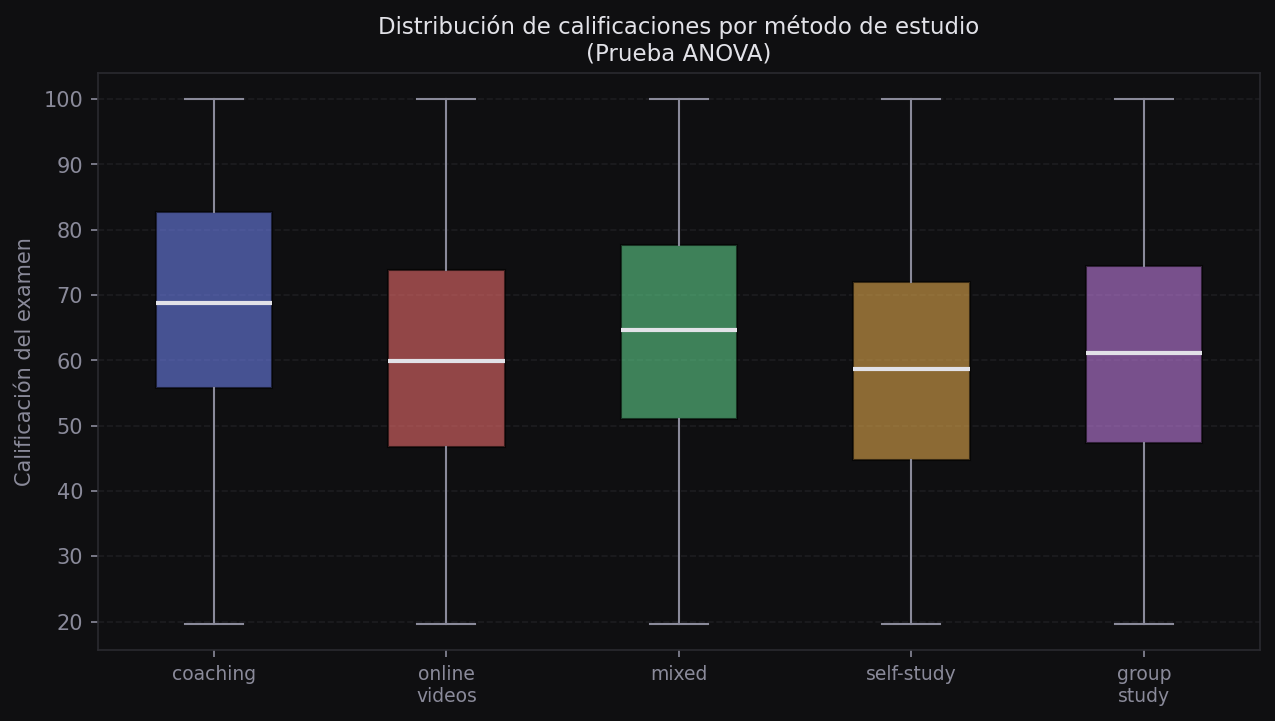
Prueba Chi-cuadrada
La prueba chi-cuadrada (\(\chi^2\)) evalúa si existe asociación entre dos variables categóricas. Compara la distribución observada de frecuencias con la distribución esperada si las variables fueran independientes.
Las hipótesis son:
- H₀: las dos variables son independientes (no hay asociación)
- Hₐ: las dos variables están asociadas
Chi-cuadrada en Python
Ejemplo: ¿existe asociación entre el género y el método de estudio?
from scipy.stats import chi2_contingency
# Paso 1: tabla de contingencias (frecuencias cruzadas)
tabla = pd.crosstab(df["gender"], df["study_method"])
print(tabla)
# Paso 2: prueba chi-cuadrada
chi2_stat, p_valor, grados_libertad, esperados = chi2_contingency(tabla)
print(f"\nEstadístico chi²: {chi2_stat:.4f}")
print(f"P-valor: {p_valor:.4f}")
print(f"Grados de libertad: {grados_libertad}")
if p_valor < 0.05:
print("Rechazamos H₀: existe asociación entre género y método de estudio.")
else:
print("No rechazamos H₀: género y método de estudio son independientes.")study_method coaching group study mixed online videos self-study
gender
female 1350 1273 1284 1323 1349
male 1315 1282 1324 1386 1388
other 1371 1367 1286 1360 1342
Estadístico chi²: 11.72
P-valor: 0.1641
No rechazamos H₀: género y método de estudio son independientes.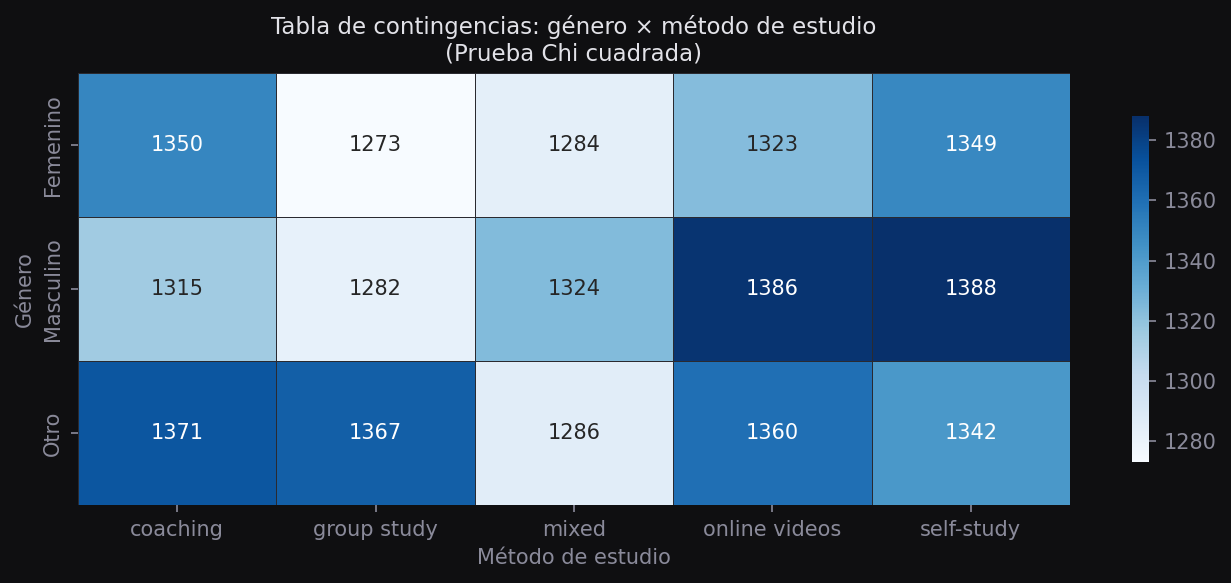
¿Cuál prueba usar?
| Variable objetivo | Variable de agrupación | Prueba |
|---|---|---|
| Numérica | Categórica — 2 grupos | t de Student |
| Numérica | Categórica — 3+ grupos | ANOVA (f_oneway) |
| Categórica | Categórica | Chi-cuadrada |
| Numérica | Numérica | Correlación de Pearson / regresión |